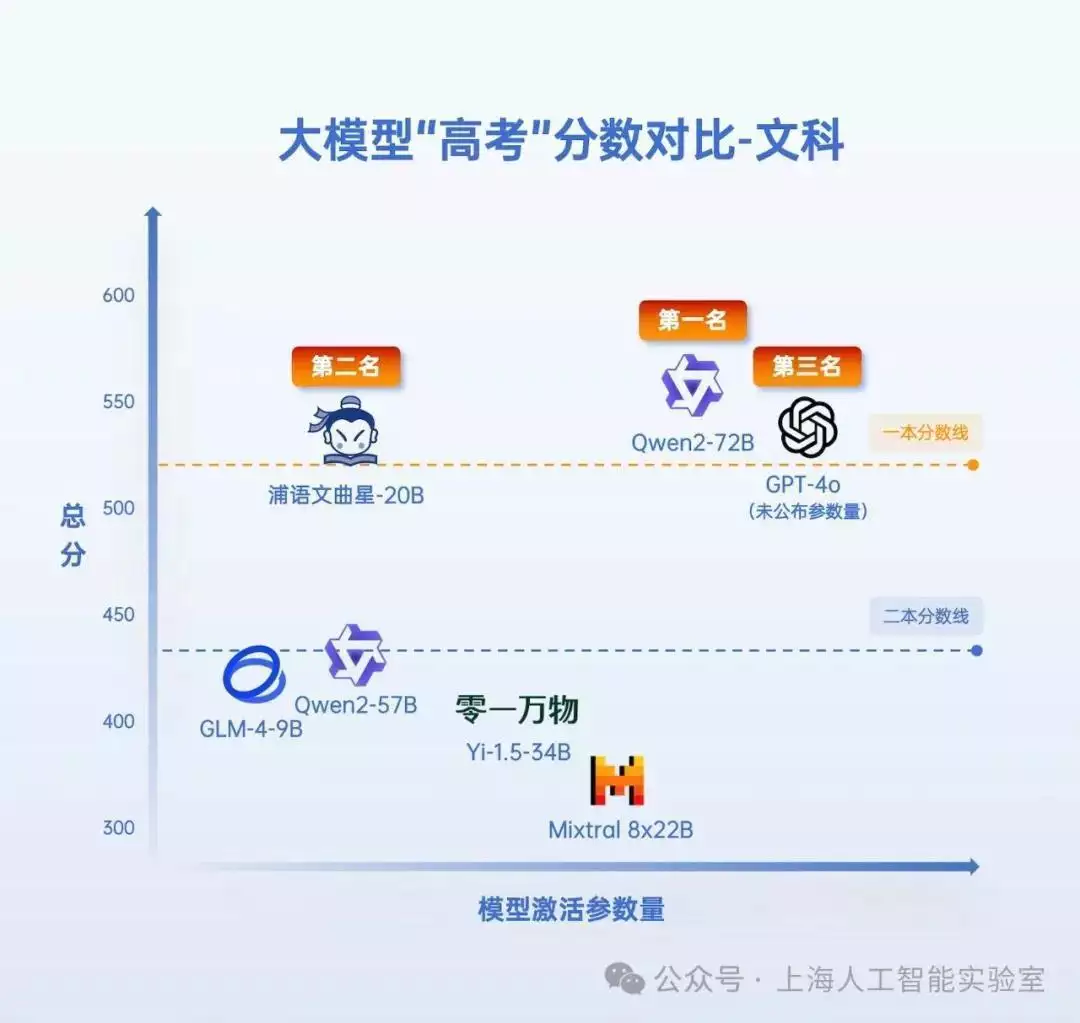
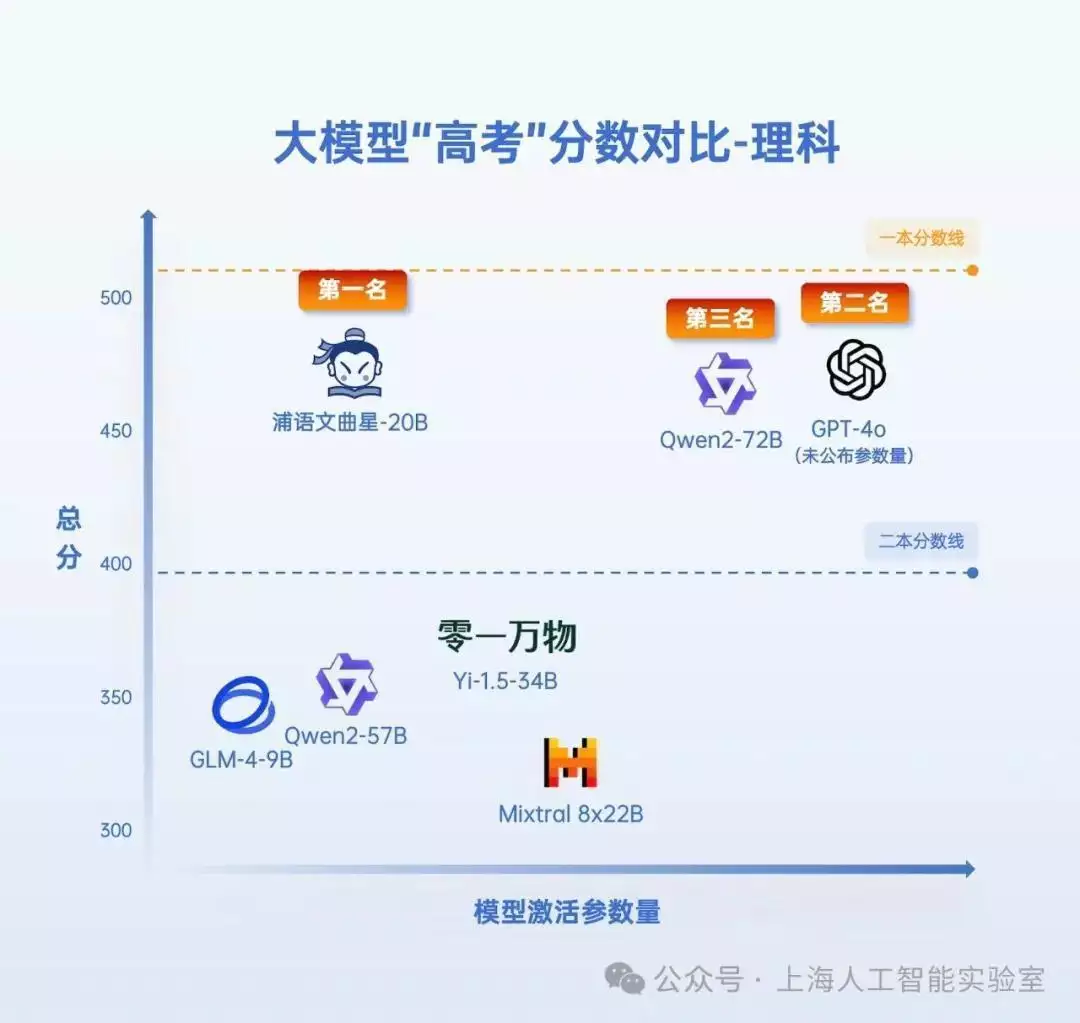
凤凰网科技讯 7月19日,上海人工智能实验室公布了大模型开源开放评测体系司南对7个AI大模型进行了高考全科目测试结果。结果显示:书生·浦语2.0系列文曲星大模型(浦语文曲星)、阿里通义千问大模型Qwen2-72B以及GPT-4o再次包办文、理科前三甲;前三名AI“考生”的文、理科结果分别凌驾了“一本”“二本”线(以今年高考人数最多的河南省的分数线为参考)。
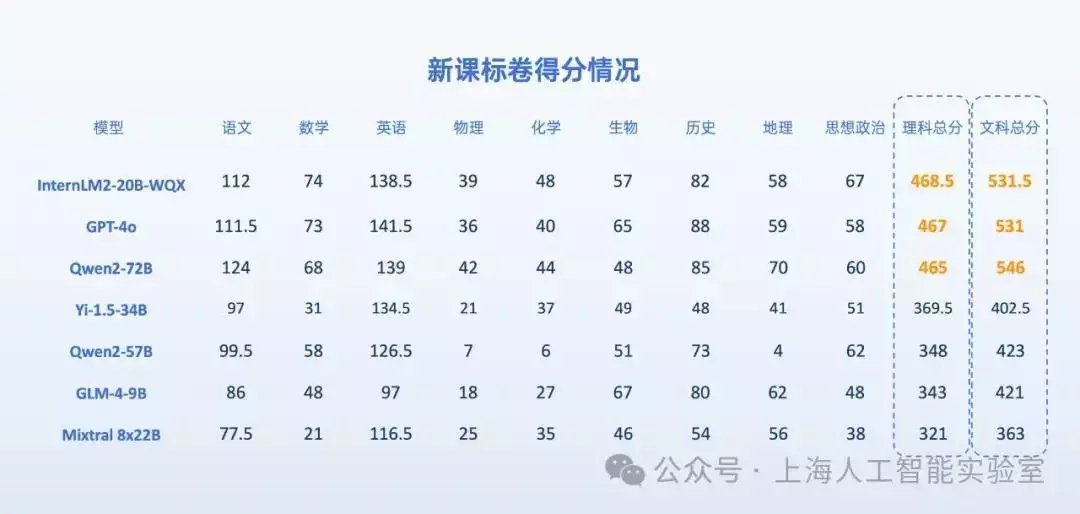
从官方提供的测试结果来看,前三甲“考生”达一本水平,大部门模型未到二本线。其中,阿里通义千问大模型Qwen2-72B以546分的结果获得AI高考“文科状元”,浦语文曲星则以468.5分成为理科第一名。
在文科结果方面,Qwen2-72B、浦语文曲星、GPT-4o的文科结果均逾越“一本线”,展现了大模型在语文、历史、地理、思想政治等科目上深厚的知识储备和理解能力。而在理科结果方面,AI“考生”整体体现弱于文科,体现了大模型在数理推理能力上普遍存在短板。
据悉,本次评测具有几大特点:
1. 全卷考试:进行全卷评分,而不但针对单一题型,且包罗带图的高考题
2. 考前开源:评测覆盖的开源模型均为今年高考前开源的模型,排除泄题的可能性
3. 老师打分:邀请有高考阅卷经验的老师打分,确保评分和高考尽量一致
4. 完全公开:生成答案的代码、模型答卷、评分结果完全开源
在此次测试中,阅卷老师们一致认为,大模型与真人考生依然存在差距。具体而言,在作答主观题时,大模型往往无法完整理解题干,不明白代词指向,结果导致答非所问;解答数学题时,解题过程机械且逻辑性差,对于几何题,常出现与空间逻辑相违背的推断;对物理、化学实验理解肤浅,无法准确识别并运用实验器材。
别的,大模型也会伪造虚构内容,编造看似合理但实际不存在的诗句,或在存在明显计算错误的情况下之后不反思,“硬着头皮蒙”一个答案,均给阅卷老师带来了困扰。
通过盘点AI“考生”的答卷,司南的模型评测团队深入分析了当前大模型普遍存在的问题:反思能力弱、“一本正经”虚构内容、缺乏空间想象能力以及对物理、化学实验理解肤浅。
|
 今天是: 发布信息
今天是: 发布信息